מה זה כל האסקים, UTFים וכל קידודים האלה?
נתחיל מהאב הקדמון- קוד מורס האגדי. קוד מורס הומצא כשיטה להעביר הודעה דרך אמצעים אלקטרונים ולתרגם את הצלילים המועברים לאותיות. את ההודעה בונים בעזרת תקשורת בינארית(בתוספת של רווח בין הצלילים)- נקודה או קו. כך למשל את ההודעה “SOS” שכולנו מכירים, אפשר לקרוא בקוד מורס כ- “… - - - …”, ואם נשמע את הצליל של ההודעה הזאת, הוא יהיה מאוד מוכר לכולנו מאיפשהוא (כי טחנו את הצליל בכל מקום בסרטים הישנים).
קוד מורס שירת את האנושות עד עליית המחשבים והתקשורת בין המחשבים, המשתמשת בתקשורת בינארית של 0 ו-1, דאז האנושות הייתה צריכה להתקדם קצת ולמצוא דרך חדשה לתרגם את המידע שנשמר או נשלח ברשת בצורה של 0 או 1’ים- לתווים ומספרים ממשיים.
אז שיטות להפיכת מספרים רגילים לבינאריים וההפך- היה לנו. 1 זה 1, 2 זה 10, 3 זה 11 וכל’. אבל לתווים- לא היה לנו.
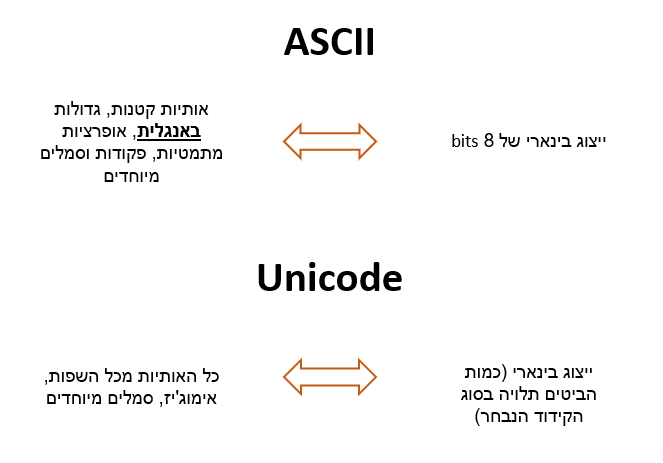
ואז נולדה לה טבלת ה- ASCII, שהיא מכילה את כל התווים של המקלדת שלכם, כש-33 התווים הראשונים מיוחסים ל"פקודות" כמו SPACE, TAB, ESC , ו-65 עד 127 לשאר התווים כמו אותיות קטנות וגדולות (באנגלית בלבד- זה חשוב), + - = וכל’. הטבלת ASCII הראשונית הייתה מוגדרת ל- 7 ביטים לייצוג תו, כך שיש 128 אפשרויות סה"כ. עכשיו אפשר לחזור אחריי: 1000001 זה A, ו- 1000010 זה B. הוריי אפשר לתרגם תווים מבינארית לאנגלית!
על אף ההתקדמות המטאורית, שאפילו בעזרת טבלת ASCII הטיסו חללית לירח, היה נחוץ בעוד פריצת דרך: אנחנו רוצים להעביר תווים בינלאומיים בכל העולם, ולא רק באנגלית. מה עם קצת אותיות בסינית, רוסית ועברית? ומה עם קצת אימוג’יז?
שוב נכנסנו להריון והפעם הולדנו את ה- Unicode, שהיא טבלה שאפתנית המאכלסת את כל התווים בעולם- עברית, רוסית, יפנית, אימוג’י, ועוד (לכל תו יש “code point” שהוא המזהה הייחודי שלו בטבלה). עכשיו יש לנו טבלה משודרגת, וכל שנותר לנו הוא לייחס כל תוו לייצוג הבינארי שלו. לשם כך נוצרו להם קידודים שונים עם חוקים משלהם.
כאן נכנס UTF-8 לתמונה. UTF-8 בהגדרתו הוא שימוש ב-8 ביטים לפחות לייצוג של תוו כלשהוא, הכולל את השימוש הרגיל של ה- ASCII שלנו. זה אומר, שהייצוג של A ב-UTF8 יהיה 01000001. גם ב- ASCII אגב הורחבו התווים מ-128 אפשרויות ל- 256 אפשרויות, כיאה לקומבינציות של byte אחד.
מחיפוש בגוגל נתון שיש כ- 143,859 תווים ל-unicode, אבל התשובה כנראה מורכבת יותר. בכל מקרה, זה הרבה מעל ל-256 האפשרויות שיש בבייט אחד. אז מה עושים? ממשיכים לעוד בייט, ועוד בייט עד 6 בייטים (כלומר הקפיצות יהיו של bytes).
ומה עם UTF 16, 32? אותו רעיון- הייצוג של כל תו יהיה לפי 16 או 32 ביטים בהתאמה. לפי ההיגיון UTF-8 נשמע יעיל יותר, מכיוון שכל תוו מיוצג במינימום של 8 ביטים, בזמן שהאחרים ע"י 16 ו-32, אבל זה לא מדויק. ישנם מקרים בהם דווקא להשתמש ב 16-UTF יעיל יותר (כמו בשפות אסיאתיות מסוימות), שכן פרזנטציות של אותיות בשפות מסויימות ב- 8UTF יהיו בגודל 4 בייטים, וב-16 יהיו בגודל 2 בייטים. בנוסף, מכיוון שטבלת ASCII תומכת בייצוג של 8 ביטים לתו, אז קידודים כמו 16,32 UTF לא ייתמכו במערכות המתבססות על ASCII.
לקינוח, מה זה בדיוק codec? זה פשוט הסוג של הקידוד שאנחנו משתמשים בו. UTF-8 למשל, הוא סוג של codec.