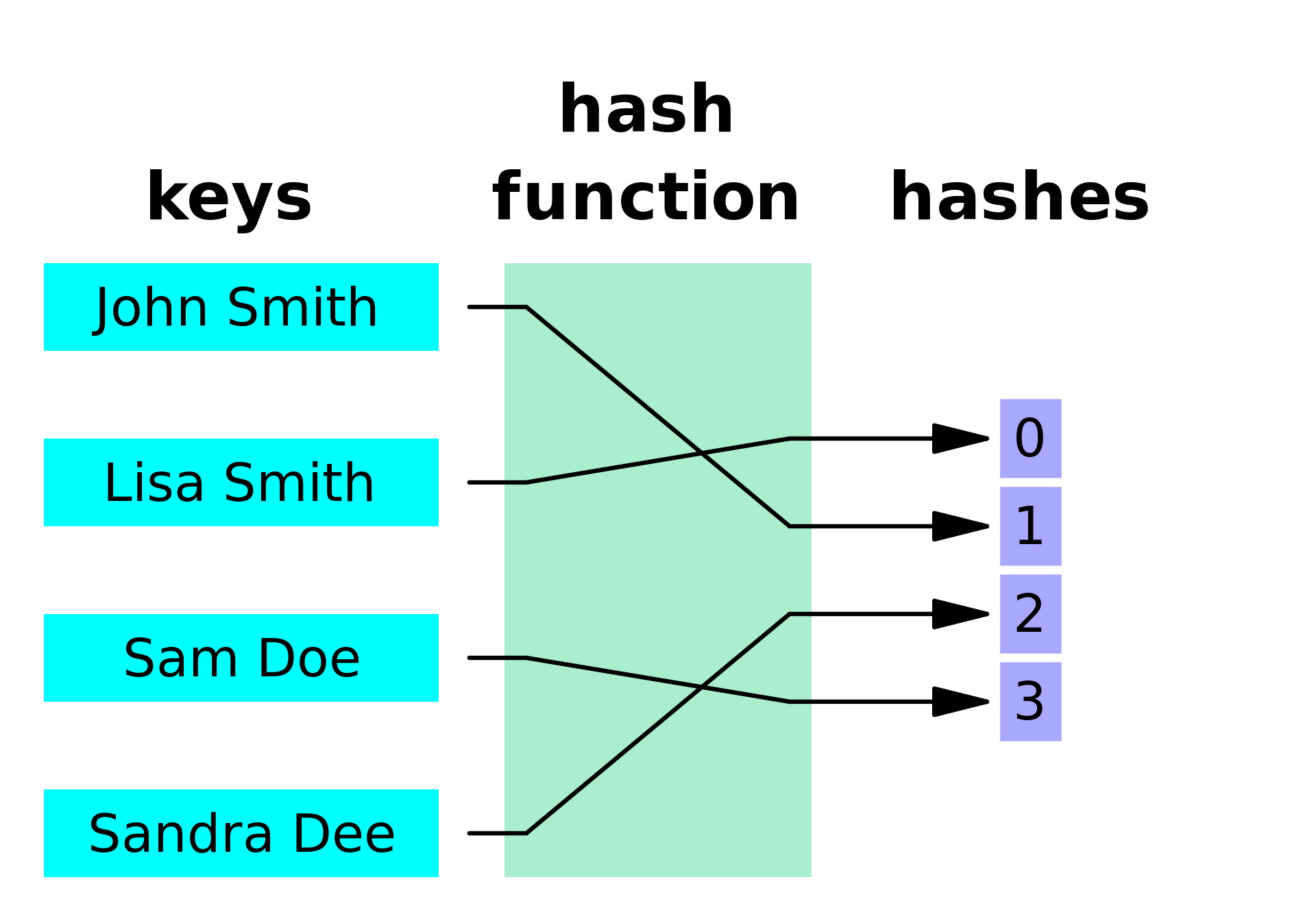
המימוש הכי בסיסי של hash table הוא מערך פשוט, עם אינדקס והערך המיוחל שאנחנו רוצים לשמור ו\או לשלוף…ב-O1. אבל בשביל להשיג O1 אנחנו צריכים את האינדקס שבו שמור הערך שלנו. מכיוון שאיננו מקבלים את האינדקס (ומה הטעם?), אז למעשה אנחנו לא יכולים להגיע ל O1. או שאולי כן?
הפתרון מיושם בעזרת random access + hash functions כדי ליצור מקומות אקראיים, בהתבסס על המפתח שאנחנו מכניסים למערך. אנחנו מבצעים פעולת ‘האש’ על המפתח, מייצרים אינדקס ‘רנדומלי’- ומכניסים אותו למערך. לפי השיטה הזאת, תיאורטית, אנחנו יכולים למצוא את האינדקס של הערך כל פעם אם אנחנו מספקים את המפתח.
לדוגמא, אם נחליט שפונקציית ההאש שלנו היא “לקחת את האות הראשונה של המפתח, והמרתה לגימטריה”, נקבל שהאינדקס של המפתח ‘המבורגר’ הוא 5, ושל ‘פיצה’ 80. במקרה הזה אנחנו מכניסים ומוציאים ב- O1.
הדוגמה מעליי בעצם פותרת לנו את הבעיה, ומאפשרת לנו להכניס ערכים במקומות רנדומלים, ולדעת מה האינדקס שלהם ולשלוף אותם במהירות, אם יש לנו perfect hash function- פונקציה חד חד ערכית בין קבוצת המפתחות, וקבוצת האינדקסים המיוצרים לאחר הפעלת ההאש.
אבל כמובן, הדוגמה מעליי היא נאיבית ומייצרת בעיה קשה (שגם אלגוריתמים פחות נאיבים מייצרים).
אם ניחשתם נכון, אז שמתם לב שאנחנו יכולים בקלות לקבל כפילויות באינדקסים. אם ננסה להכניס ‘פלפל’ למערך שלנו, אנחנו נקבל את האינדקס 80…שיט. הבעיה נקראת hash collision, וככל שפונקציית ההאש שלנו יותר נאיבית (לא טובה או מתאימה), כך הסיכויי שלנו לכפילויות גדל, אבל לא נעלם. ההוכחה היא פשוטה: מכיוון שפונקציות האש מאפשרות להכניס קלט אינסופי ופולטות קלט סופי, אז בהכרח יהיו כפילויות בפלטים (עקרון שובך היונים).
בנוסף, מכיוון שמערכי hash tables הם בעלי אורך סופי (11 למשל), אנחנו נצטרך לעשות מודולו על תוצאת האינדקס עם אורך המערך כדי למנוע יצירת אינדקס הגדול מגודל המערך (וגם מוביל לכפילויות).
מכיוון שאי אפשר ‘באמת’ לפתור את הבעיה, בדר"כ משתמשים ב-2 כיסתוחים פופולאריים.
הראשון מביניהם הוא יצירת ‘רשימה בתוך רשימה’, כלומר linkedlist בתוך ה- hash table שלנו. לפי הדוגמה של הפלפל והפיצה שלנו, שניהם נכנסים תחת האינדקס 80. הפיצה נכנסת ראשונה, וכשאנחנו מכניסים את הפלפל, אנחנו מכניסים לפיצה מצביע לפלפל. בחיפוש שלנו, נגיע לאינדקס 80, ומשם נחפש את הפלפל או הפיצה. אנחנו אמנם לא מגיעים ל- O1 טהור אבל אנחנו דיי קרובים לשם.
הכיסתוח השני הוא פשוט להפעיל עוד פונקציית האש על התוצאה הראשונה. עוד אופציה היא לחפש את האינדקס הכי קרוב ל-80 שפנוי ולהכניסו לשם (נקרא גם open addressing).
בכל האופציות הללו, ה-worst case יהיה O(N), כי במקסימום לכולם יהיה את אותו האינדקס.
לפונקציית ההאש של ה-hash tables יש משמעות קריטית בביצועים שלה. אם נבחר פונקציה לא נכונה, נקבל הרבה כפילויות שיאטו את כל האופרציות שלנו. אם נבחר פונקציית האש איטית מידי, נקבל תמיד ביצועים נמוכים. עדיין חשוב לזכור שכפילויות הם לא דבר כל כך נפוץ (אך שוב, קיים), ולכן hash tables הם בכל זאת פתרון אידיאלי למי שצריך, לפחות, O1 lookup.